This will aid them in developing products that people need and also moving ahead of their competitors. Web scratching needs two parts, namely the spider and also the scrape. The spider is an expert system algorithm that browses the internet to look for the certain data called for by adhering to the links across the internet. The scrape, on the other hand, is a specific tool produced to draw out information from the website. The design of the scrape can vary significantly according to the complexity as well as scope of the job to ensure that it can swiftly as well as properly remove the information. If there's information on an internet site, then in theory, it's scrapable!
- The data collected with internet scraping ought to be used responsibly as well as morally.
- Despite the fact that internet scraping has so many efficient uses, as is the case with lots of innovations, cyber offenders have actually also located ways of abusing it
- This is why a lot of the globe's famous firms rely on ScrapeHero for its information.
- If you're Automated Web Scraping interested interested in get information ditched for you, you can have a look at our internet scuffing solutions ParseHub And also.
- Additionally, you can utilize web scuffing to consolidate details from report.
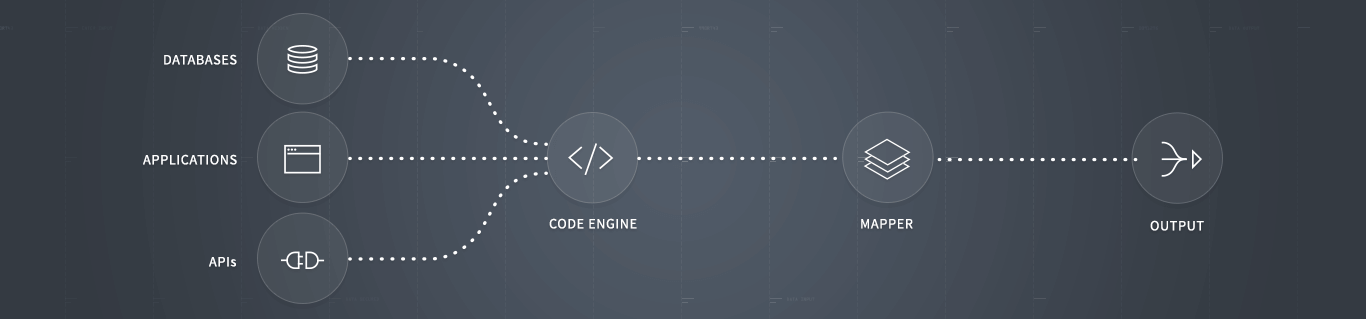
Selenium WebDriver can be quickly integrated right into this procedure to accumulate information. Abigail Jones The Octoparse information professional will certainly share you with some beneficial information regarding Octoparse. Allow's begin with just how Octoparse resolves one of Data Scraping Experts the most usual troubles in web scuffing.
Dataforest Is Acknowledged By Goodfirms As The Best Company To Work With
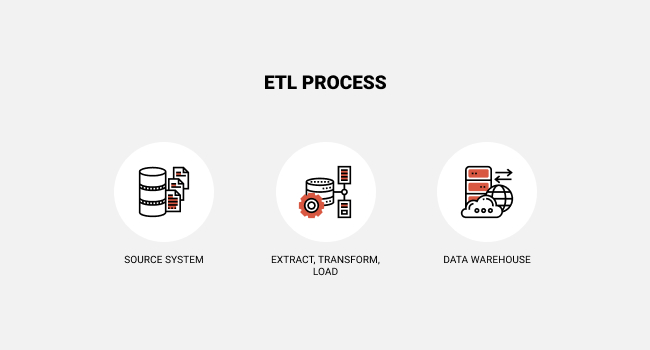
Well, you can replicate as well as paste the details from Wikipedia to your very own documents. [newline] Yet suppose you want to obtain big quantities of information from a website as swiftly as feasible? Such as large amounts of data from a web site to educate a Machine Learning formula? Internet scuffing describes the removal of data from a web site. In many cases, this is done using software tools such as internet scrapers.
UK's Oldest Daily Newspaper Apparently First Stop On Clearview's ... - Techdirt
UK's Oldest Daily Newspaper Apparently First Stop On Clearview's ....
Posted: Wed, 23 Aug 2023 20:52:00 GMT [source]
Store the drawn out data in an ideal style, such as a CSV or JSON documents, or a data source. If you intend to have the ability to engage with the page (click on a switch, scroll, etc) then you will certainly need to use your own Selenium, Puppeteer, or Headache headless Web Scraping web browser. When doing so you should always configure your scrape to send its demands to our proxy port, not the API endpoint; otherwise, your headless internet browser may not work appropriately. Of course, having the ability to do more parallel demands implies quicker scratching times as you can get more HTML reactions per min.
How Popular Is Internet Scratching?
Then the Internet grows, ultimately coming to be the residence to millions of web pages that contain a wide range of data in numerous forms, consisting of texts, images, videos, and sound. What Is Web Rub-- Essential & Practical Usesupdated in 2022 to obtain an extra detailed understanding of web scratching and its pros and cons.
As an option, there are web scraping devices automating web data extraction at fingertips. Web scuffing is the procedure of instantly mining information or accumulating info from the Net. An additional kind of malicious internet scraping is "over-scraping," where scrapes send a lot of demands over a given duration.
More recent forms of internet scuffing include checking information feeds from web servers. For instance, JSON is frequently used as a transport system in between the client as well as the web server. While web scraping is an effective device, it additionally presents a powerful danger to many web hosts. Whatever side of the server you're on, every person has a beneficial interest in making sure that internet scraping is utilized responsibly and, obviously, completely. While some anti-scraping measures are difficult to bypass, there are a number of approaches that often tend to work usually.